Having the various vocabularies available online and accessible via web services we’re now in a position to create widgets (functional user interface controls) making use of the vocabularies. For this exercise we don’t really have to create anything new at all, just repurpose one of the nice examples from the jQuery UI site. We will create a type-ahead drop down autocompletion term suggestion control (à la Google), but employing domain specific vocabulary.
All SENESCHAL web services support JSONP callbacks allowing you to call them remotely to retrieve and display terminology from within your own web page. Our data source will be the SENESCHAL getConceptLabelMatch web service, and we will reuse elements of the JQUERY UI (remote JSONP) example. This example will keep the coding minimal for clarity, but of course you are free to introduce other bells and whistles as required. The first thing is to include references to the jQuery and jQueryUI scripts, and a basic stylesheet. So in your page header include the following lines:
<head>
<script src="http://code.jquery.com/jquery-1.11.0.min.js"></script>
<script src="http://code.jquery.com/ui/1.10.3/jquery-ui.js"></script>
<link rel="stylesheet" href="http://code.jquery.com/ui/1.10.3/themes/smoothness/jquery-ui.css" />
</head>
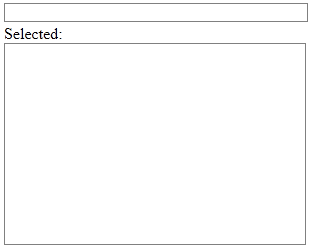
We will have a text box from which the term suggestions will drop down in response to typing, and a <div> element to display any selected suggestions as a link (I’ve used a bit of optional minor inline CSS styling here):
<body>
<input id="suggestions" style="width: 300px; border: 1px solid gray;margin-bottom: 3px;"/>
<br><label>Selected:</label><br>
<div id="selected" style="height: 200px; width: 300px; border: 1px solid gray; overflow: auto;"></div>
</body>
These elements should render something like the screen dump below:
Now for the data source. The service call takes (among others) a ‘schemeURI’ parameter to specify the URI of a concept scheme the suggestions will originate from (URI is case sensitive). There is also a ‘startsWith’ parameter to search for labels that start with this text, or alternatively a ‘contains’ parameter. There is also an optional ‘limit’ parameter to specify the maximum number of records to return. Putting this together into an example gives us:
http://www.heritagedata.org/live/services/getConceptLabelMatch?schemeURI=http://purl.org/heritagedata/schemes/eh_period&startsWith=EARLY&limit=3
This call searches the periods list for the first 3 terms starting with “EARLY”. The response is a JSON array structure, containing the matching label, the label language and (importantly) the Linked Data URI for each concept:
[
{
"uri":"http://purl.org/heritagedata/schemes/eh_period/concepts/UM",
"label":"EARLY MED. OR LATER",
"label lang":"en"
},
{
"uri":"http://purl.org/heritagedata/schemes/eh_period/concepts/EM",
"label":"EARLY MEDIEVAL",
"label lang":"en"
},
{
"uri":"http://purl.org/heritagedata/schemes/eh_period/concepts/EIA",
"label":"EARLY IRON AGE",
"label lang":"en"
}
]
We now need to specify that the “#suggestions” element is to act as an autocomplete widget. The jQueryUI autocomplete control ‘minLength’ parameter controls how many characters are typed before it attempts a remote service call – we will use a value of 3. The ‘source’ parameter can either be a static JSON array structure in the format [{label: ‘abc’, value: ‘def’}] – or a function returning that format. We can encapsulate the service call into a Javascript AJAX call, and map the resultant data to the required structure. Finally the ‘select’ parameter is a function determining what to do when an item is selected from the drop down list of suggestions. So this time finding the first 5 terms containing the specified text from the periods thesaurus, within a <script> tag:
<script>
$(function() {
$("#suggestions").autocomplete({
source: function(request, response) {
$.ajax({
url: "http://www.heritagedata.org/live/services/getConceptLabelMatch",
cache: true,
dataType: "jsonp",
data: {
schemeURI: "http://purl.org/heritagedata/schemes/eh_period",
contains: request.term,
limit: 5
},
success: function(data) {
response($.map(data, function(item) {
return { label: item.label.toUpperCase(), value: item.uri }
}));
}
});
},
minLength: 3,
select: function(event, ui) {
if(ui.item) {
$("<div>").html("<a href='" + ui.item.value + "'>" + ui.item.label + "</a>").prependTo("#selected");
$(this).val(ui.item.label);
}
else $(this).val("");
return false;
}
});
});
</script>
Now a set of suggestions should drop down after the 3rd character is typed into the upper text box (there may be a short delay for the service call to complete and return data). If we select any of these suggestions it is recorded into the lower box as a link containing the Linked Data URI of the selected concept, and the selected label fills the upper box. We could still ignore these suggestions, but this ‘progressive enhancement’ of the original text box allows us to offer selections from a controlled terminology without necessarily becoming intrusive or dictatorial about it.
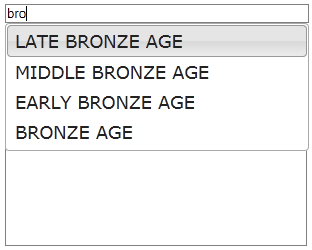

Term suggestion, in a widget. A short example pulls this all together into a single HTML page. Feel free to download and experiment with it. Although this is a fairly simple example it is also quite powerful, as we can index data using the same domain specific vocabularies, referencing the same unique identifiers, from anywhere. Now try changing the ‘schemeURI’ parameter in the code to suggest terms from any of the other vocabularies hosted on HeritageData. Hopefully this has been a useful starting point that shows how you could incorporate SENESCHAL web service calls into your own systems.